Anuncio publicitario
Si tu ejecutar un sitio web 10 formas de crear un sitio web pequeño y simple sin la exageraciónWordPress puede ser una exageración. Como lo demuestran estos otros excelentes servicios, WordPress no es el final de la creación de sitios web. Si desea soluciones más simples, hay una variedad para elegir. Lee mas , probablemente haya oído hablar de un archivo robots.txt (o del "estándar de exclusión de robots"). Ya sea que lo haya hecho o no, es hora de conocerlo, porque este simple archivo de texto es una parte crucial de su sitio. Puede parecer insignificante, pero es posible que se sorprenda de lo importante que es.
Veamos qué es un archivo robots.txt, qué hace y cómo configurarlo correctamente para su sitio.
¿Qué es un archivo robots.txt?
Para comprender cómo funciona un archivo robots.txt, necesita saber un poco sobre los motores de búsqueda ¿Cómo funcionan los motores de búsqueda?Para muchas personas, Google ES Internet. Podría decirse que es el invento más importante desde la propia Internet. Y aunque los motores de búsqueda han cambiado mucho desde entonces, los principios subyacentes siguen siendo los mismos. Lee mas . La versión corta es que envían "rastreadores", que son programas que buscan información en Internet. Luego almacenan parte de esa información para poder dirigir a las personas a ella más tarde.
Estos rastreadores, también conocidos como "bots" o "arañas", encuentran páginas de miles de millones de sitios web. Los motores de búsqueda les dan instrucciones sobre a dónde ir, pero los sitios web individuales también pueden comunicarse con los bots y decirles qué páginas deben mirar.
La mayoría de las veces, en realidad hacen lo contrario y les dicen qué páginas no debería estar mirando. Cosas como páginas administrativas, portales de backend, páginas de categorías y etiquetas, y otras cosas que los propietarios de sitios no quieren que se muestren en los motores de búsqueda. Estas páginas siguen siendo visibles para los usuarios y cualquier persona que tenga permiso (que suele ser todo el mundo) puede acceder a ellas.
Pero al decirles a esas arañas que no indexen algunas páginas, el archivo robots.txt les hace un favor a todos. Si buscó "MakeUseOf" en un motor de búsqueda, ¿le gustaría que nuestras páginas administrativas aparecieran en los primeros lugares de la clasificación? No. Eso no le haría ningún bien a nadie, así que le decimos a los motores de búsqueda que no los muestren. También se puede utilizar para evitar que los motores de búsqueda revisen páginas que podrían no ayudarlos a clasificar su sitio en los resultados de búsqueda.
En resumen, robots.txt le dice a los rastreadores web qué hacer.
¿Pueden los rastreadores ignorar el archivo robots.txt?
¿Los rastreadores alguna vez ignoran los archivos robots.txt? Si. De hecho, muchos rastreadores hacer ignoralo. Sin embargo, por lo general, esos rastreadores no proceden de motores de búsqueda de buena reputación. Provienen de spammers, recolectores de correo electrónico y otros tipos de bots automatizados Cómo construir un rastreador web básico para extraer información de un sitio web¿Alguna vez quisiste capturar información de un sitio web? A continuación, le mostramos cómo escribir un rastreador para navegar por un sitio web y extraer lo que necesita. Lee mas que deambulan por Internet. Es importante tener esto en cuenta: Usar el estándar de exclusión de robots para decirles a los bots que se mantengan alejados no es una medida de seguridad efectiva.. De hecho, algunos bots pueden comienzo con las páginas a las que les dices que no vayan.
Sin embargo, los motores de búsqueda harán lo que indique su archivo robots.txt siempre que tenga el formato correcto.
Cómo escribir un archivo robots.txt
Hay algunas partes diferentes que se incluyen en un archivo estándar de exclusión de robots. Los desglosaré individualmente aquí.
Declaración de agente de usuario
Antes de decirle a un bot qué páginas no debe mirar, debe especificar con qué bot está hablando. La mayoría de las veces, usará una declaración simple que significa "todos los bots". Eso se ve así:
Agente de usuario: *El asterisco representa "todos los bots". Sin embargo, puede especificar páginas para ciertos bots. Para hacer eso, necesitará saber el nombre del bot para el que está estableciendo las pautas. Eso podría verse así:
Usuario-agente: Googlebot. [lista de páginas para no rastrear] Usuario-agente: Googlebot-Image / 1.0. [lista de páginas para no rastrear] Agente de usuario: Bingbot. [lista de páginas para no rastrear]Etcétera. Si descubre un bot que no desea que rastree su sitio en absoluto, también puede especificarlo.
Para encontrar los nombres de los agentes de usuario, visite useragentstring.com [Ya no está disponible].
Rechazar páginas
Esta es la parte principal de su archivo de exclusión de robots. Con una simple declaración, le dices a un bot o grupo de bots que no rastreen ciertas páginas. La sintaxis es sencilla. A continuación, le indicamos cómo no permitiría el acceso a todo el contenido del directorio "admin" de su sitio:
No permitir: / admin /Esa línea evitaría que los bots rastreen yoursite.com/admin, yoursite.com/admin/login, yoursite.com/admin/files/secret.html y cualquier otra cosa que pertenezca al directorio de administración.
Para no permitir una sola página, simplemente especifíquela en la línea de no permitir:
No permitir: /public/exception.htmlAhora la página de "excepción" no se dibujará, pero todo lo demás en la carpeta "pública" sí.
Para incluir varios directorios o páginas, simplemente indíquelos en las líneas siguientes:
No permitir: / privado / No permitir: / admin / No permitir: / cgi-bin / No permitir: / temp /Esas cuatro líneas se aplicarán a cualquier agente de usuario que haya especificado en la parte superior de la sección.
Si desea evitar que los bots vean cualquier página de su sitio, use esto:
No permitir: /Estableciendo diferentes estándares para los bots
Como vimos anteriormente, puede especificar ciertas páginas para diferentes bots. Combinando los dos elementos anteriores, esto es lo que parece:
Usuario-agente: googlebot. No permitir: / admin / No permitir: / private / User-agent: bingbot. No permitir: / admin / No permitir: / privado / No permitir: / secreto /Las secciones "administración" y "privada" serán invisibles en Google y Bing, pero Google verá el directorio "secreto", mientras que Bing no.
Puede especificar reglas generales para todos los bots utilizando el agente de usuario de asterisco y luego dar instrucciones específicas a los bots en las secciones siguientes.
Poniendolo todo junto
Con el conocimiento anterior, puede escribir un archivo robots.txt completo. Simplemente encienda su editor de texto favorito (estamos fans de Sublime 11 consejos de texto sublimes para la productividad y un flujo de trabajo más rápidoSublime Text es un editor de texto versátil y un estándar de oro para muchos programadores. Nuestros consejos se centran en la codificación eficiente, pero los usuarios generales apreciarán los atajos de teclado. Lee mas por aquí) y comience a informar a los bots que no son bienvenidos en ciertas partes de su sitio.
Si desea ver un ejemplo de un archivo robots.txt, diríjase a cualquier sitio y agregue "/robots.txt" al final. Esta es una parte del archivo robots.txt de Giant Bicycles:
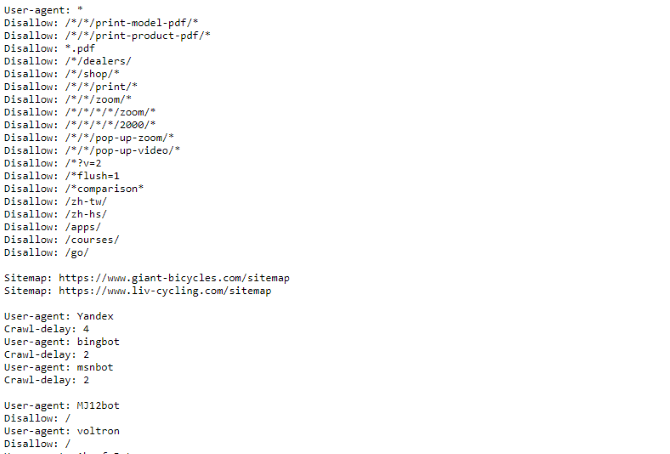
Como puede ver, hay bastantes páginas que no quieren que aparezcan en los motores de búsqueda. También han incluido algunas cosas de las que aún no hemos hablado. Veamos qué más puede hacer en su archivo de exclusión de robots.
Localización de su mapa del sitio
Si su archivo robots.txt le dice a los bots dónde no para ir, tu mapa del sitio hace lo contrario Cómo crear un mapa del sitio XML en 4 sencillos pasosHay dos tipos de mapas del sitio: una página HTML o un archivo XML. Un mapa del sitio HTML es una sola página que muestra a los visitantes todas las páginas de un sitio web y, por lo general, tiene enlaces a esas ... Lee mas y les ayuda a encontrar lo que buscan. Y aunque los motores de búsqueda probablemente ya sepan dónde está su mapa del sitio, no está de más hacérselo saber de nuevo.
La declaración para la ubicación de un mapa del sitio es simple:
Mapa del sitio: [URL del mapa del sitio]Eso es todo.
En nuestro propio archivo robots.txt, se ve así:
Mapa del sitio: //www.makeuseof.com/sitemap_index.xmlEso es todo al respecto.
Configuración de un retraso de rastreo
La directiva de demora de rastreo le dice a ciertos motores de búsqueda con qué frecuencia pueden indexar una página en su sitio. Se mide en segundos, aunque algunos motores de búsqueda lo interpretan de manera ligeramente diferente. Algunos ven un retraso de rastreo de 5 como una indicación de que esperen cinco segundos después de cada rastreo para iniciar el siguiente. Otros lo interpretan como una instrucción para rastrear solo una página cada cinco segundos.
¿Por qué le diría a un rastreador que no se arrastre tanto como sea posible? Para preservar el ancho de banda 4 formas en que Windows 10 está desperdiciando su ancho de banda de Internet¿Windows 10 está desperdiciando su ancho de banda de Internet? A continuación, le indicamos cómo verificarlo y qué puede hacer para detenerlo. Lee mas . Si su servidor tiene dificultades para mantenerse al día con el tráfico, es posible que desee instituir un retraso de rastreo. En general, la mayoría de la gente no tiene que preocuparse por esto. Sin embargo, es posible que los sitios grandes con mucho tráfico quieran experimentar un poco.
A continuación, le indicamos cómo establecer un retraso de rastreo de ocho segundos:
Retraso de rastreo: 8Eso es todo. No todos los motores de búsqueda obedecerán su directiva. Pero no está de más preguntar. Al igual que con las páginas que no permiten, puede establecer diferentes retrasos de rastreo para motores de búsqueda específicos.
Subiendo su archivo robots.txt
Una vez que haya configurado todas las instrucciones en su archivo, puede subirlo a su sitio. Asegúrese de que sea un archivo de texto sin formato y que tenga el nombre robots.txt. Luego cárguelo en su sitio para que pueda encontrarlo en yoursite.com/robots.txt.
Si usa un sistema de gestión de contenidos Los 10 sistemas de gestión de contenido más populares en líneaLos días de las páginas HTML codificadas a mano y el dominio de CSS han quedado atrás. Instale un sistema de administración de contenido (CMS) y en minutos podrá tener un sitio web para compartir con el mundo. Lee mas como WordPress, probablemente hay una forma específica en la que necesitará hacerlo. Debido a que difiere en cada sistema de administración de contenido, deberá consultar la documentación de su sistema.
Algunos sistemas también pueden tener interfaces en línea para cargar su archivo. Para estos, simplemente copie y pegue el archivo que creó en los pasos anteriores.
Recuerde actualizar su archivo
El último consejo que le daré es que revise ocasionalmente su archivo de exclusión de robots. Su sitio cambia y es posible que deba realizar algunos ajustes. Si observa un cambio extraño en el tráfico de su motor de búsqueda, es una buena idea revisar también el archivo. También es posible que la notación estándar cambie en el futuro. Como todo lo demás en su sitio, vale la pena revisarlo de vez en cuando.
¿De qué páginas excluye a los rastreadores de su sitio? ¿Ha notado alguna diferencia en el tráfico de los motores de búsqueda? ¡Comparte tus consejos y comentarios a continuación!
Dann es un consultor de marketing y estrategia de contenido que ayuda a las empresas a generar demanda y clientes potenciales. También escribe en un blog sobre estrategia y marketing de contenidos en dannalbright.com.


