Anuncio
¿Crees en la idea de que una vez que algo se publica en Internet, se publica para siempre? Bueno, hoy vamos a disipar ese mito.
La verdad es que en muchos casos es muy posible erradicar la información de Internet. Claro, hay un registro de páginas web que se han eliminado si busca Wayback Machine, ¿derecho? Sí, absolutamente En Wayback Machine hay registros de páginas web que se remontan a muchos años, páginas que no encontrará con una búsqueda de Google porque la página web ya no existe. Alguien lo eliminó o el sitio web se cerró.
Entonces, no hay forma de evitarlo, ¿verdad? La información quedará grabada para siempre en la piedra de Internet, ¿allí para que la vean generaciones? Bueno no exactamente.
La verdad es que si bien puede ser difícil o imposible borrar las principales noticias que han proliferado de un sitio web o blog de noticias a otro como un virus, En realidad, es bastante fácil erradicar por completo una página web o varias páginas web de todos los registros de existencia; eliminar esa página tanto para los motores de búsqueda como para la
Wayback Machine La nueva máquina Wayback le permite viajar visualmente en el tiempo de InternetParece que desde el lanzamiento de Wayback Machine en 2001, los propietarios del sitio han decidido deshacerse del back-end basado en Alexa y rediseñarlo con su propio código fuente abierto. Después de realizar pruebas con el ... Lee mas . Hay una trampa, por supuesto, pero llegaremos a eso.3 formas de eliminar páginas de blog de la red
El primer método es el que utilizan la mayoría de los propietarios de sitios web, porque no conocen mejor, simplemente borrando páginas web. Esto puede suceder porque te has dado cuenta de que tienes contenido duplicado en tu sitio o porque tienes una página que no quieres que aparezca en los resultados de búsqueda.
Simplemente elimine la página
El problema con la eliminación completa de páginas de su sitio web es que ya ha establecido la página en neto, es probable que haya enlaces desde su propio sitio, así como enlaces externos desde otros sitios a ese sitio en particular página. Cuando lo elimina, Google reconoce de inmediato esa página suya como una página que falta.
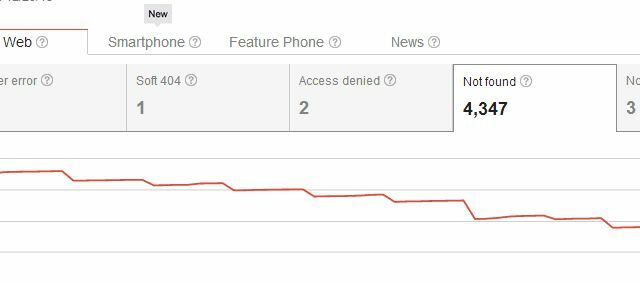
Por lo tanto, al eliminar su página, no solo ha creado un problema con los errores de rastreo "No encontrado" para usted, sino que también ha creado un problema para cualquiera que alguna vez haya vinculado a la página. Por lo general, los usuarios que acceden a su sitio desde uno de esos enlaces externos verán su página 404, que no es un problema importante, si usa algo como el código 404 personalizado de Google para dar a los usuarios sugerencias útiles o alternativas. Pero, usted pensaría que podría haber formas más elegantes de eliminar páginas de los resultados de búsqueda sin iniciar todos esos 404 para enlaces entrantes existentes, ¿verdad?
Pues los hay.
Eliminar una página de los resultados de búsqueda de Google
En primer lugar, debe comprender que si la página web que desea eliminar de los resultados de búsqueda de Google no es una página de su propio sitio, entonces no tiene suerte a menos que haya razones legales o si el sitio ha publicado su información personal en línea sin su permiso. Si ese es el caso, entonces use Google solucionador de problemas de eliminación para enviar una solicitud para eliminar la página de los resultados de búsqueda. Si tiene un caso válido, puede encontrar cierto éxito al eliminar la página; por supuesto, podría tener un éxito aún mayor solo contactando al propietario del sitio web Cómo eliminar información personal falsa en InternetLa privacidad en línea ya no está garantizada. Aprenda cómo informar un sitio web y eliminar información personal de Internet. Lee mas como describí cómo hacerlo en 2009.
Ahora, si la página que desea eliminar de los resultados de búsqueda está en su propio sitio, tiene suerte. Todo lo que necesitas hacer es crear un robots.txt archivo y asegúrese de que no ha permitido la página específica que no desea en los resultados de búsqueda o el directorio completo con el contenido que no desea indexar. Así es como se ve el bloqueo de una sola página.
Agente de usuario: * No permitir: /my-deleted-article-that-i-want-removed.html
Puede impedir que los robots rastreen directorios completos de su sitio de la siguiente manera.
Agente de usuario: * No permitir: / content-about-personal-stuff /
Google tiene una excelente Pagina de soporte eso puede ayudarlo a crear un archivo robots.txt si nunca antes ha creado uno. Esto funciona extremadamente bien, como expliqué recientemente en un artículo sobre estructurando acuerdos de sindicación Cómo negociar ofertas de sindicación y proteger sus clasificaciones de búsquedaLa sindicación está de moda en estos días. ¡Pero de repente podrías encontrar que el socio de sindicación aparece más alto que tú en los resultados de búsqueda de una historia que escribiste originalmente! Protege tus rankings de búsqueda. Lee mas para que no te lastimen (pidiendo a los socios de distribución que no permitan la indexación de sus páginas donde estás sindicado). Una vez que mi propio socio de distribución accedió a hacer esto, las páginas que contenían contenido duplicado de mi blog desaparecieron por completo de las listas de búsqueda.
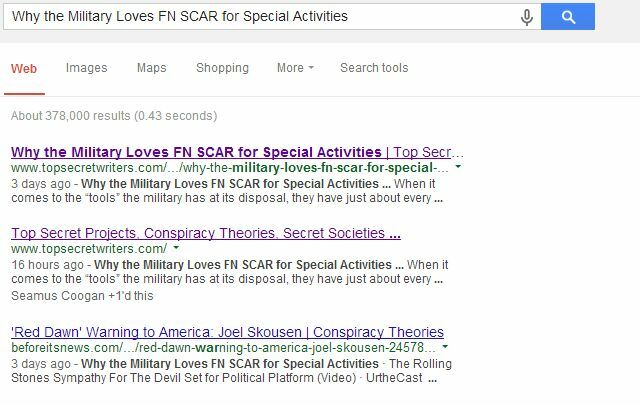
Solo el sitio web principal aparece en el tercer lugar de la página donde enumeran nuestro título, pero mi blog ahora aparece en el primer y segundo lugar; algo que habría sido casi imposible si un sitio web de mayor autoridad dejara indexada la página duplicada.
Lo que mucha gente no se da cuenta es que esto también es posible lograr con el Archivo de Internet (la Máquina Wayback). Estas son las líneas que debe agregar a su archivo robots.txt para que esto suceda.
Usuario-agente: ia_archiver. No permitir: / sample-category /
En este ejemplo, le digo a Internet Archive que elimine todo lo que se encuentre en el subdirectorio de la categoría de muestra en mi sitio de la Máquina Wayback. El archivo de Internet explica cómo hacerlo en su página de ayuda de Exclusion. Aquí también es donde explican que "Internet Archive no está interesado en ofrecer acceso a sitios web u otros documentos de Internet cuyos autores no desean que sus materiales estén en la colección".
Esto es contrario a la creencia común de que todo lo publicado en Internet se acumula en el archivo por toda la eternidad. No: los webmasters que poseen el contenido pueden eliminar específicamente el contenido del archivo mediante el enfoque de robots.txt.
Eliminar una página individual con metaetiquetas
Si solo tiene algunas páginas individuales que desea eliminar de los resultados de la Búsqueda de Google, en realidad no tiene que usar el enfoque de robots.txt en absoluto, simplemente puede agregar la metaetiqueta "robots" correcta a las páginas individuales y decirles a los robots que no indexen ni sigan enlaces en toda la página página.

Puede usar el meta "robots" anterior para evitar que los robots indexen la página, o podría decirle específicamente al robot de Google no indexar para que la página solo se elimine de los resultados de búsqueda de Google, y otros robots de búsqueda aún puedan acceder a la página contenido.
Depende completamente de usted cómo le gustaría administrar lo que hacen los robots con la página y si la página aparece o no en la lista. Para unas pocas páginas individuales, este puede ser el mejor enfoque. Para eliminar un directorio completo de contenido, vaya con el método robots.txt.
La idea de "eliminar" contenido
Este tipo de cosas da vuelta la noción de "borrar contenido de Internet". Técnicamente, si elimina todos sus propios enlaces a una página de su sitio, y lo elimina de la Búsqueda de Google y el Internet Archive usando la técnica de robots.txt, la página es para todos los propósitos "eliminados" de Internet. Sin embargo, lo bueno es que si hay enlaces existentes a la página, esos enlaces seguirán funcionando y no activará errores 404 para esos visitantes.
Es un enfoque más "suave" para eliminar contenido de Internet sin alterar por completo la popularidad de enlaces existente de su sitio en Internet. Al final, la forma en que gestionas el contenido que recopilan los motores de búsqueda y el Archivo de Internet depende de ti, pero siempre recuerde que a pesar de lo que la gente dice sobre la vida útil de las cosas que se publican en línea, realmente está completamente dentro de su controlar.
Ryan tiene una licenciatura en ingeniería eléctrica. Ha trabajado 13 años en ingeniería de automatización, 5 años en TI y ahora es ingeniero de aplicaciones. Ex editor jefe de MakeUseOf, ha hablado en conferencias nacionales sobre visualización de datos y ha aparecido en la televisión y radio nacionales.


